一、深度学习的概念及成就
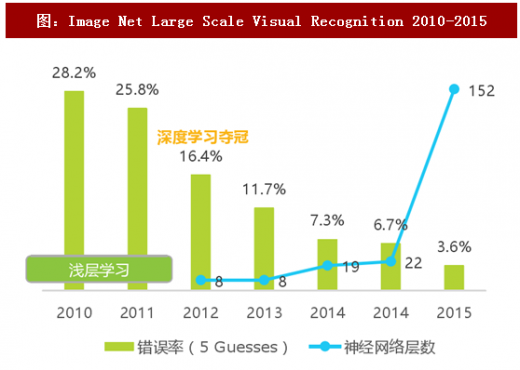
深度学习算法由多重非线性变换构成多个处理层,辅以复杂结构设计和各种梯度技术,通过对大量样本的输入与对应输出数据的抽象计算,拟合出一个可处理新输入信息的函数模型,解决其分类或预测问题。尽管神经网络(可理解为深度学习算法的前身或别称)的研究历史其实比计算机视觉的研究历史还要长,但在之前的研究过程中,深度神经网络的方法并未得到有效验证。直到2011年,语音识别领域凭借深度学习取得重大突破;2012年,AlexNet,一个8层的神经网络,以超越第二名10个百分点的成绩在ImageNet竞赛中夺冠(图像分类的Top 5错误率为16.4%),深度学习终迎来包括学术探索与工业应用中的热潮。不断提升的层数逐步提升计算机分类视觉的准确率,2015年夺冠的 ResNet 深达152层,以3.57%的错误率超越人类视觉的5.1%。
传统方法,针对不同类别的物体,一般首先由研究员充分发挥聪明才智,手工定义不同的特征,然后利用不同的机器学习算法(分类器学习),这时的算法一般仅有两到三次非线性变换,学到的参数较少(浅层学习);深度学习则通过机器学习自身来产生特征,因此特征和分类器学习不再有区分。如今深度学习的算法已可达上千层。

参考观研天下发布《2016-2022年中国学习机行业竞争现状及十三五市场竞争态势报告》
二、数据与算力是深度学习的重要支撑
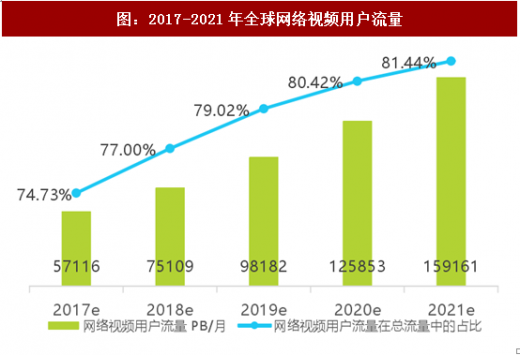
日益丰富的影像内容为深度学习算法提供了大量的数据支撑。据思科公司评估,2021年单月上传至全球网络的视频总时长将超过500万年,每秒将诞生1百万分钟的网络视频内容,网络视频流量将占据全球所有网络用户流量的81.44%。需要说明的是,现在的学习多为有监督学习(需要对数据进行充分标注),而且并非所有类型的影像数据都易得易标注(比如医疗影像数据需由专业医师标注病灶),业界领先的视觉公司一般会有数百人的标注团队(多为外包,但需专业培训,实时指导)。
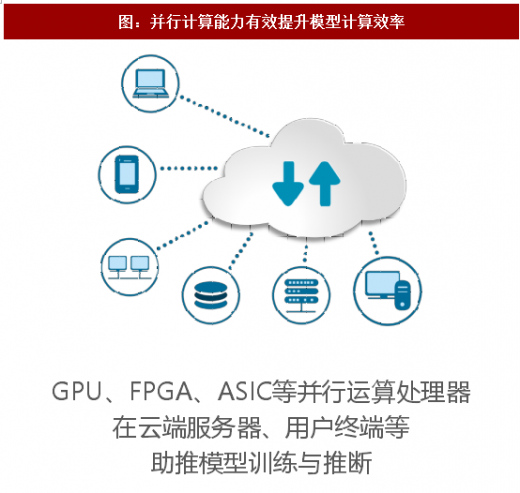
另一方面,深度学习学习过程中的“训练”与应用部署后的“推断”均涉及大量并行计算,传统CPU算力不足,而GPU、FPGA (现场可编程门阵列) 、ASIC (TPU、NPU等AI专属架构芯片)等具有良好并行计算能力的芯片可提供数十倍乃至于上百倍于CPU的性能,与云服务一起,大幅缩短计算过程(在过去,往往数周甚至数月才能跑出一次结果,然后调整模型架构,效率极低),易于短期调整多种模型架构,显著提升分类模型的进步速度。2010年以后,CPU内部晶体管数量的增长明显放缓,传统摩尔定律失效, 而GPU类处理器依然保持着快速增长的势头(2016年GPU的计算力为10 个TFLOP/S ,2017年达到了120个TFLOP/S ,TPU则实现了惊人的180个TFLOP/S ),验证着AI时代的摩尔定律。
三、人脸识别是当下视觉领域热门应用的重要技术支撑
人脸识别可看做语义感知任务中针对人脸影像的分类问题,也是当下视觉领域热门应用的重要技术支撑,各个环节都因深度学习算法的推进实现了更优的计算结果。泛金融领域的远程身份认证、手机领域的刷脸解锁一般属于人脸验证(技术相对成熟);安防影像分析一般为人脸识别,刑侦破案对亿级甚至十亿级比对有刚性需求,目前技术仍有很大进步空间,更多新功能、新场景的解锁依赖于最先进的算法团队和相关业务领域开拓者的共同努力。
深度学习算法由多重非线性变换构成多个处理层,辅以复杂结构设计和各种梯度技术,通过对大量样本的输入与对应输出数据的抽象计算,拟合出一个可处理新输入信息的函数模型,解决其分类或预测问题。尽管神经网络(可理解为深度学习算法的前身或别称)的研究历史其实比计算机视觉的研究历史还要长,但在之前的研究过程中,深度神经网络的方法并未得到有效验证。直到2011年,语音识别领域凭借深度学习取得重大突破;2012年,AlexNet,一个8层的神经网络,以超越第二名10个百分点的成绩在ImageNet竞赛中夺冠(图像分类的Top 5错误率为16.4%),深度学习终迎来包括学术探索与工业应用中的热潮。不断提升的层数逐步提升计算机分类视觉的准确率,2015年夺冠的 ResNet 深达152层,以3.57%的错误率超越人类视觉的5.1%。
传统方法,针对不同类别的物体,一般首先由研究员充分发挥聪明才智,手工定义不同的特征,然后利用不同的机器学习算法(分类器学习),这时的算法一般仅有两到三次非线性变换,学到的参数较少(浅层学习);深度学习则通过机器学习自身来产生特征,因此特征和分类器学习不再有区分。如今深度学习的算法已可达上千层。

图:深度学习与传统方法的区别

图:Image Net Large Scale Visual Recognition 2010-2015
参考观研天下发布《2016-2022年中国学习机行业竞争现状及十三五市场竞争态势报告》
二、数据与算力是深度学习的重要支撑
日益丰富的影像内容为深度学习算法提供了大量的数据支撑。据思科公司评估,2021年单月上传至全球网络的视频总时长将超过500万年,每秒将诞生1百万分钟的网络视频内容,网络视频流量将占据全球所有网络用户流量的81.44%。需要说明的是,现在的学习多为有监督学习(需要对数据进行充分标注),而且并非所有类型的影像数据都易得易标注(比如医疗影像数据需由专业医师标注病灶),业界领先的视觉公司一般会有数百人的标注团队(多为外包,但需专业培训,实时指导)。
另一方面,深度学习学习过程中的“训练”与应用部署后的“推断”均涉及大量并行计算,传统CPU算力不足,而GPU、FPGA (现场可编程门阵列) 、ASIC (TPU、NPU等AI专属架构芯片)等具有良好并行计算能力的芯片可提供数十倍乃至于上百倍于CPU的性能,与云服务一起,大幅缩短计算过程(在过去,往往数周甚至数月才能跑出一次结果,然后调整模型架构,效率极低),易于短期调整多种模型架构,显著提升分类模型的进步速度。2010年以后,CPU内部晶体管数量的增长明显放缓,传统摩尔定律失效, 而GPU类处理器依然保持着快速增长的势头(2016年GPU的计算力为10 个TFLOP/S ,2017年达到了120个TFLOP/S ,TPU则实现了惊人的180个TFLOP/S ),验证着AI时代的摩尔定律。

图:2017-2021年全球网络视频用户流量

图:并行计算能力有效提升模型计算效率
三、人脸识别是当下视觉领域热门应用的重要技术支撑
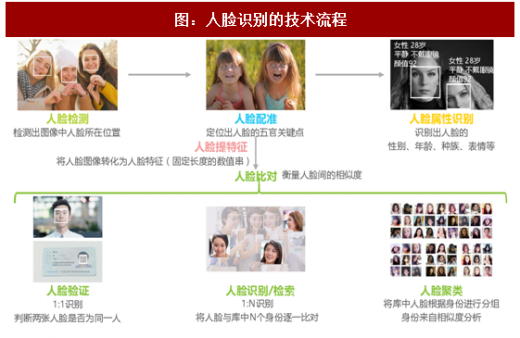
人脸识别可看做语义感知任务中针对人脸影像的分类问题,也是当下视觉领域热门应用的重要技术支撑,各个环节都因深度学习算法的推进实现了更优的计算结果。泛金融领域的远程身份认证、手机领域的刷脸解锁一般属于人脸验证(技术相对成熟);安防影像分析一般为人脸识别,刑侦破案对亿级甚至十亿级比对有刚性需求,目前技术仍有很大进步空间,更多新功能、新场景的解锁依赖于最先进的算法团队和相关业务领域开拓者的共同努力。

图:人脸识别的技术流程
资料来源:观研天下整理,转载请注明出处(ZQ)
更多好文每日分享,欢迎关注公众号

【版权提示】观研报告网倡导尊重与保护知识产权。未经许可,任何人不得复制、转载、或以其他方式使用本网站的内容。如发现本站文章存在版权问题,烦请提供版权疑问、身份证明、版权证明、联系方式等发邮件至kf@chinabaogao.com,我们将及时沟通与处理。