1、A.I需要GPU加速计算
当前的A.I可以划分为两个阶段:学习阶段和推理阶段。前者是通过对训练数据进行学习,形成经验的过程,为A.I独立解决问题做准备。后者是利用学习阶段学习到的经验解决A.I遇到的实时、变化的问题的过程。学习过程比推理过程更为复杂,对处理能力要求更高。学习部分是驱动A.I增加处理能力需求的主要因素,训练类神经网络需要对海量信息进行处理运算,学习阶段的一般做法是将训练负载切割成许多同时执行的工作任务,因此能够进行浮点运算及并行运算的处理器是学习阶段的主要需求。
学习阶段主要在数据中心完成,对处理器的运算性能要求较高。由于学习阶段是在数据中心中对海量数据进行离线处理,所以学习阶段对A.I芯片的运算性能要求较高,对芯片功耗、价格不敏感。
推理阶段多用于消费前端,更看重处理器的性能功耗比及成本。在推理阶段,神经网络只需将输入数据带入已经训练好的算法中,得到与之映射的输出结果。一般发生在应用前端,是对已经训练好的模型进行实时应用。其运算能力要求没有学习阶段强,但是要求处理器能适用前端环境。因此推理阶段更为注重的是处理器的性能功耗比和价格。
GPU性能高、功耗大、价格高,适用于学习阶段(数据中心)。GPU在并行计算、浮点以及矩阵运算方面具有强大的性能,但是其功耗较大、价格较高。但这些对于数据中心来说都不是太大问题。数据中心作为A.I深度学习高性能计算平台,快速完成对海量数据的多层次、多迭代模型分析处理才是关键。目前采用GPU加速的服务器已经可将训练速度提高5~10倍,这对于A.I研发人员来说可以加快其成果转化速度。从2011年,人工智能研究人员首次使用英伟达GPU为深度学习加速后,GPU在A.I领域发挥的巨大作用逐渐被人认识。越来越多的数据中心采用GPU加速方案来提速深度学习,GPU也开始向通用GPU方向发展。
2、GPU在A.I数据中心广泛应用
随着人工智能的不断渗透,GPU被越来越多地应用到数据中心提供深度学习并行计算加速。从2011年首次被应用到A.I,经过几年发展,GPU通用性越来越强,并行计算能力越来越高,已经将深度学习训练时间从数周缩短到几天。几乎所有互联网巨头都在依靠强大的GPU加速深度学习应用,处理复杂的算法及海量的数据,提高人工智能运行速度和执行效果。微软发布的CNTK(ComputationalNetworkToolkit)开源深度学习神经网络工具包,就是基于英伟达GPU开发的。CNTK(ComputationalNetworkToolkit,即计算网络工具包),是微软研究院开发的开源深度学习神经网络工具包,最多支持8个GPU并行运算。
Facebook于今年3月份发布的A.I训练服务器—BigBasin服务器,就是由配臵英伟达GPU的服务器搭建起来的。该服务器比之前的BigSur快了近一倍,训练规模也大了30%。该服务器可以帮助Facebook进行图像、面部识别、实时翻译、理解并描述图片和视频内容,为Facebook提供更多的应用以吸引用户。
虽然一些其他芯片厂商也在研发基于FPGA或者ASIC的A.I芯片。但不得不承认GPU广泛用于各种深度学习平台,已经成为了不可忽视的事实。
GPU+CPU异构架构成为面向A.I服务器的主流架构。随着计算复杂度的逐步提升,服务器采用的处理系统并未单纯的只有GPU或GPU,而是由CPU和GPU组合而成的异构系统,两种处理器各取所长,密集的处理任务交给GPU,复杂的逻辑运算交给CPU,两种处理器协同工作,提升系统的运算速率。在A.I处理需求带动下,异构系统越来越普遍,GPU的市场需求也会进一步的扩大。BernsteinResearch统计数据表明,随着GPU+CPU异构系统越来越多地应用到A.I领域,GPU价格在数据中心成本占比越来越高。
参考中国报告网发布《2016-2022年中国图形处理器(GPU)行业现状调查及竞争策略分析报告》

3、龙头厂商深耕A.I处理器市场
GPU的广泛使用使得传统GPU厂商受益。随着GPU在数据中心的广泛使用,GPU龙头厂商获益,数据显示,自从2011年GPU应用于人工智能领域以来,英伟达作为最有竞争力的GPU厂商,成为芯片市场的宠儿。其营业收入自2011年以来一直保持高速增长,且最近一个财年度营业收入增长了37.92%。
图形处理厂商向A.I厂商转型。GPU概念的首次提出,还是在1999年英伟达发布其GeForce256图形处理芯片时。GPU的出现减轻了CPU的工作负载,减少了图形显示任务对CPU的依赖,使得计算机图形处理能力得到快速提升。公司在独立显卡领域一直占据着绝对的竞争优势。随着GPU通用计算能力被发掘,英伟达在数据中心市场获益。看到A.I广阔的应用前景后,公司也从之前的图形处理公司开始转型成A.I创业公司。
英伟达继续在A.I数据中心端、云端发力,研发各个平台的GPU加速解决方案。英伟达开发的NVIDIADGX-1人工智能超级计算机,是世界上首台专为深度学习和人工智能加速分析而打造的系统,性能堪比250台传统服务器,将神经网络训练时间从原来的几个月缩短到了几天。除此之外,在今年5月的GTC大会上,英伟达推出了TeslaV100新款GPU和HGX-1云服务器。TeslaV100GPU研发投入高达30亿美元,是当前英伟达产品中性能最强大的加速卡,单个计算单元比上一代同架构计算卡快了12倍。HGX-1云服务器配备了8块TeslaV100GPU,适用于公有云、深度学习、图形渲染、CUDA计算等。目前,国内外已有众多云服务商宣布将使用TeslaV100GPU或搭载了该产品的云服务器,国外有亚马逊AWS云、微软Azure云等,国内有阿里云、百度云、腾讯云等。另外,英伟达还推出了NvidiaGPUCloud,该产品为用户提供云端硬件和软件接口,用户可通过接口快速构建、训练和部署神经网络模型。

英伟达开始向前端推理应用领域发力。继无人驾驶计算平台—NVIDIADRIVEPX2平台之后,英伟达近期推出了新一代深度学习应用平台TensorRT3。TensorRT3是一款可编程应用平台,训练好的神经网络可以简便的通过该平台部署到其搭载的GPU硬件上,最快只需要几秒钟,需要的人工操作也非常少。和前几代TensorRT相比,新一代平台几乎覆盖了市面上所有深度学习开源框架,支持的GPU种类也增多,能够处理的深度学习应用也更加丰富。
从英伟达推出DRIVEPX2和TensorRT3这两个平台可以看出,英伟达正试图在人工智能的前端推理应用领域拓展其在学习训练领域的领先地位,建立自己的生态圈子。在今年9月份举行的GTCChina(GPU技术大会中国分会)上,英伟达一反常态,并没有继续介绍其在人工智能学习训练领域的辉煌战绩,推出的新品与宣布的合作案例大多集中在深度学习推理应用领域,例如,宣布与海康威视合作打造AI城市,与京东在仓储机器人与送货无人机方面进行合作。目前,英伟达的GPU已经被安防、自动驾驶等众多企业应用于终端产品进行推理计算。
我们认为目前人工智能应用领域的发展速度快于底层芯片的发展速度,GPU是目前发展最为完善的一类AI芯片,是现阶段人工智能应用开发的首选,英伟达凭借其GPU的先发优势在人工智能的前端推理应用领域抢占了先机。但是前端电子产品对AI芯片运算性能、价格、能耗等方面的要求相较于后端数据中心更为苛刻,手机等消费电子的竞争甚至对于芯片有极致的性能要求,GPU这样一款从图形图像处理器转型而来的AI芯片产品不能包打天下,基于FPGA、ASIC的AI定制芯片大有可为,同样蕴藏巨大机会。
当前的A.I可以划分为两个阶段:学习阶段和推理阶段。前者是通过对训练数据进行学习,形成经验的过程,为A.I独立解决问题做准备。后者是利用学习阶段学习到的经验解决A.I遇到的实时、变化的问题的过程。学习过程比推理过程更为复杂,对处理能力要求更高。学习部分是驱动A.I增加处理能力需求的主要因素,训练类神经网络需要对海量信息进行处理运算,学习阶段的一般做法是将训练负载切割成许多同时执行的工作任务,因此能够进行浮点运算及并行运算的处理器是学习阶段的主要需求。
学习阶段主要在数据中心完成,对处理器的运算性能要求较高。由于学习阶段是在数据中心中对海量数据进行离线处理,所以学习阶段对A.I芯片的运算性能要求较高,对芯片功耗、价格不敏感。
推理阶段多用于消费前端,更看重处理器的性能功耗比及成本。在推理阶段,神经网络只需将输入数据带入已经训练好的算法中,得到与之映射的输出结果。一般发生在应用前端,是对已经训练好的模型进行实时应用。其运算能力要求没有学习阶段强,但是要求处理器能适用前端环境。因此推理阶段更为注重的是处理器的性能功耗比和价格。
GPU性能高、功耗大、价格高,适用于学习阶段(数据中心)。GPU在并行计算、浮点以及矩阵运算方面具有强大的性能,但是其功耗较大、价格较高。但这些对于数据中心来说都不是太大问题。数据中心作为A.I深度学习高性能计算平台,快速完成对海量数据的多层次、多迭代模型分析处理才是关键。目前采用GPU加速的服务器已经可将训练速度提高5~10倍,这对于A.I研发人员来说可以加快其成果转化速度。从2011年,人工智能研究人员首次使用英伟达GPU为深度学习加速后,GPU在A.I领域发挥的巨大作用逐渐被人认识。越来越多的数据中心采用GPU加速方案来提速深度学习,GPU也开始向通用GPU方向发展。
2、GPU在A.I数据中心广泛应用
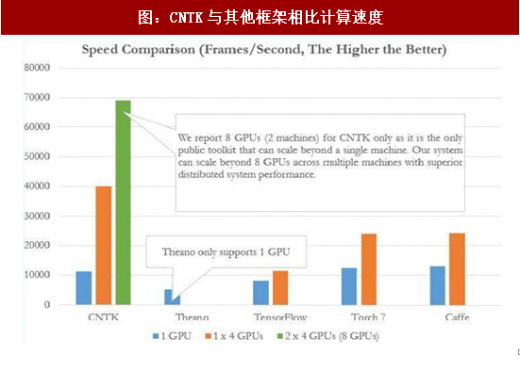
随着人工智能的不断渗透,GPU被越来越多地应用到数据中心提供深度学习并行计算加速。从2011年首次被应用到A.I,经过几年发展,GPU通用性越来越强,并行计算能力越来越高,已经将深度学习训练时间从数周缩短到几天。几乎所有互联网巨头都在依靠强大的GPU加速深度学习应用,处理复杂的算法及海量的数据,提高人工智能运行速度和执行效果。微软发布的CNTK(ComputationalNetworkToolkit)开源深度学习神经网络工具包,就是基于英伟达GPU开发的。CNTK(ComputationalNetworkToolkit,即计算网络工具包),是微软研究院开发的开源深度学习神经网络工具包,最多支持8个GPU并行运算。

图:CNTK与其他框架相比计算速度
资料来源:观研天下整理
Facebook于今年3月份发布的A.I训练服务器—BigBasin服务器,就是由配臵英伟达GPU的服务器搭建起来的。该服务器比之前的BigSur快了近一倍,训练规模也大了30%。该服务器可以帮助Facebook进行图像、面部识别、实时翻译、理解并描述图片和视频内容,为Facebook提供更多的应用以吸引用户。

图:Facebook的A.I训练服务器——BigBasin
资料来源:观研天下整理
虽然一些其他芯片厂商也在研发基于FPGA或者ASIC的A.I芯片。但不得不承认GPU广泛用于各种深度学习平台,已经成为了不可忽视的事实。
GPU+CPU异构架构成为面向A.I服务器的主流架构。随着计算复杂度的逐步提升,服务器采用的处理系统并未单纯的只有GPU或GPU,而是由CPU和GPU组合而成的异构系统,两种处理器各取所长,密集的处理任务交给GPU,复杂的逻辑运算交给CPU,两种处理器协同工作,提升系统的运算速率。在A.I处理需求带动下,异构系统越来越普遍,GPU的市场需求也会进一步的扩大。BernsteinResearch统计数据表明,随着GPU+CPU异构系统越来越多地应用到A.I领域,GPU价格在数据中心成本占比越来越高。
参考中国报告网发布《2016-2022年中国图形处理器(GPU)行业现状调查及竞争策略分析报告》

图:异构系统服务器中GPU占总成本比例
资料来源:观研天下整理
3、龙头厂商深耕A.I处理器市场
GPU的广泛使用使得传统GPU厂商受益。随着GPU在数据中心的广泛使用,GPU龙头厂商获益,数据显示,自从2011年GPU应用于人工智能领域以来,英伟达作为最有竞争力的GPU厂商,成为芯片市场的宠儿。其营业收入自2011年以来一直保持高速增长,且最近一个财年度营业收入增长了37.92%。
图形处理厂商向A.I厂商转型。GPU概念的首次提出,还是在1999年英伟达发布其GeForce256图形处理芯片时。GPU的出现减轻了CPU的工作负载,减少了图形显示任务对CPU的依赖,使得计算机图形处理能力得到快速提升。公司在独立显卡领域一直占据着绝对的竞争优势。随着GPU通用计算能力被发掘,英伟达在数据中心市场获益。看到A.I广阔的应用前景后,公司也从之前的图形处理公司开始转型成A.I创业公司。
英伟达继续在A.I数据中心端、云端发力,研发各个平台的GPU加速解决方案。英伟达开发的NVIDIADGX-1人工智能超级计算机,是世界上首台专为深度学习和人工智能加速分析而打造的系统,性能堪比250台传统服务器,将神经网络训练时间从原来的几个月缩短到了几天。除此之外,在今年5月的GTC大会上,英伟达推出了TeslaV100新款GPU和HGX-1云服务器。TeslaV100GPU研发投入高达30亿美元,是当前英伟达产品中性能最强大的加速卡,单个计算单元比上一代同架构计算卡快了12倍。HGX-1云服务器配备了8块TeslaV100GPU,适用于公有云、深度学习、图形渲染、CUDA计算等。目前,国内外已有众多云服务商宣布将使用TeslaV100GPU或搭载了该产品的云服务器,国外有亚马逊AWS云、微软Azure云等,国内有阿里云、百度云、腾讯云等。另外,英伟达还推出了NvidiaGPUCloud,该产品为用户提供云端硬件和软件接口,用户可通过接口快速构建、训练和部署神经网络模型。

图:英伟达HGX-1宣传照
资料来源:观研天下整理
英伟达开始向前端推理应用领域发力。继无人驾驶计算平台—NVIDIADRIVEPX2平台之后,英伟达近期推出了新一代深度学习应用平台TensorRT3。TensorRT3是一款可编程应用平台,训练好的神经网络可以简便的通过该平台部署到其搭载的GPU硬件上,最快只需要几秒钟,需要的人工操作也非常少。和前几代TensorRT相比,新一代平台几乎覆盖了市面上所有深度学习开源框架,支持的GPU种类也增多,能够处理的深度学习应用也更加丰富。
从英伟达推出DRIVEPX2和TensorRT3这两个平台可以看出,英伟达正试图在人工智能的前端推理应用领域拓展其在学习训练领域的领先地位,建立自己的生态圈子。在今年9月份举行的GTCChina(GPU技术大会中国分会)上,英伟达一反常态,并没有继续介绍其在人工智能学习训练领域的辉煌战绩,推出的新品与宣布的合作案例大多集中在深度学习推理应用领域,例如,宣布与海康威视合作打造AI城市,与京东在仓储机器人与送货无人机方面进行合作。目前,英伟达的GPU已经被安防、自动驾驶等众多企业应用于终端产品进行推理计算。
我们认为目前人工智能应用领域的发展速度快于底层芯片的发展速度,GPU是目前发展最为完善的一类AI芯片,是现阶段人工智能应用开发的首选,英伟达凭借其GPU的先发优势在人工智能的前端推理应用领域抢占了先机。但是前端电子产品对AI芯片运算性能、价格、能耗等方面的要求相较于后端数据中心更为苛刻,手机等消费电子的竞争甚至对于芯片有极致的性能要求,GPU这样一款从图形图像处理器转型而来的AI芯片产品不能包打天下,基于FPGA、ASIC的AI定制芯片大有可为,同样蕴藏巨大机会。
资料来源:观研天下整理,转载请注明出处(GSL)
更多好文每日分享,欢迎关注公众号

【版权提示】观研报告网倡导尊重与保护知识产权。未经许可,任何人不得复制、转载、或以其他方式使用本网站的内容。如发现本站文章存在版权问题,烦请提供版权疑问、身份证明、版权证明、联系方式等发邮件至kf@chinabaogao.com,我们将及时沟通与处理。








