CPU 难堪大任,AI 芯片站上舞台

CPU 类似流水线,而 AI 技术更需要割麦机,前者适合复杂指令,后者适合大量数据并行处理。CPU处理数据的过程类似于工厂的流水线操作,流水线可以对单线程上每个产品做出不同处理,通用性强,适合处理复杂指令,擅长逻辑控制。但是前文提到的神经网络算法则是发出简单指令,而要求快速高效的并行计算能力,需要的数据处理过程更类似与割麦机收割麦子。我们可以想象如果使用流水线收割小麦并处理将会浪费多少的时间,因此使用CPU进行深度学习的效率比较低。此外,CPU主频速度受到功耗的影响提升空间有限,架构设计更新的周期也较长,无论从性能还是匹配度方面都不能满足AI计算的算力要求。在这种环境下,并行计算能力更强、适应于AI计算的AI芯片应运而生。

GPU 因良好的矩阵计算能力和并行计算优势最早被用于 AI 计算,在数据中心中获得大量应用。GPU最早作为深度学习算法的芯片被引入人工智能领域,因其良好的浮点计算能力适用于矩阵计算,且相比CPU具有明显的数据吞吐量和并行计算优势。2011年谷歌大脑率先应用GPU芯片,当时12颗英伟达的GPU可以提供约等于2000颗CPU的深度学习性能,展示了其惊人的运算能力。目前GPU已经成为人工智能领域最普遍最成熟的智能芯片,应用于数据中心加速和部分智能终端领域,在深度学习的训练阶段其性能更是无所匹敌。
参考中国报告网发布《2018-2023年中国人工智能芯片市场发展现状与发展机遇分析报告》
FPGA 因其在灵活性和效率上的优势,适用于虚拟化云平台和预测阶段,在 2015 年后异军突起。2015年Intel收购FPGA市场第二大企业Altera,开始了FPGA在人工智能领域的应用热潮。因为FPGA灵活性较好、处理简单指令重复计算比较强,用在云计算架构形成CPU+FPGA的混合异构中相比GPU更加的低功效和高性能,适用于高密度计算,在深度学习的预测阶段有着更高的效率和更低的成本,使得全球科技巨头纷纷布局云端FPGA生态。国外包括亚马逊、微软都推出了基于FPGA的云计算服务,而国内包括腾讯云、阿里云均在2017年推出了基于FPGA 的服务,百度大脑也使用了FPGA芯片。
ASIC 芯片因其比 FPGA 芯片具备更低的能耗与更高的计算效率,适用于人工智能平台和智能终端领域的特性,一直是 AI 芯片研发领域的焦点。但是ASIC研发周期较长、商业应用风险较大等不足也使得只有大企业或背靠大企业的团队愿意投入到它的完整开发中。其中最为出名的是Google在2016年开发的张量处理单元,即TPU芯片。在2017年最新版的AlphaGo物理处理器中就有4个TPU,同时TPU也支持着Google的Cloud TPU平台和基于此的机器学习超级计算机。此外,近期由国内企业寒武纪开发的 “DIANNAO”系列芯片受到广泛关注。华为新发的麒麟 970 处理器所搭载的 NPU 就是 2016 年寒武纪发布的 1A 处理器(Cambricon-1A Processor)。
类大脑芯片则在架构上直接通过模仿大脑结构进行神经拟态计算,完全开辟了另一条实现人工智能的道路,而不是作为人工神经网络或深度学习的加速器存在。类脑芯片可以将内存、CPU和通信部件完全集成在一起,实现极高的通信效率和极低的能耗。目前该类芯片还只是小规模研究与应用,低能耗的优势也带来预测精度不高等问题,没有高效的学习算法支持使得类脑芯片的进化较慢,还不能真正实现商用。目前这方面的代表是IBM的“True North”芯片。
总结来说,基于深度学习的应用过程,AI芯片可以分为适合训练使用(GPU)和适合预测使用(FPGA,ASIC);基于最终应用场景,则可以分为数据中心应用和广义终端应用。目前有的大部分现芯片都用于了深度学习的训练阶段,而随着终端的普及以及模型训练的不断完善,预测部分的计算占比将大幅提升。

CPU 的串行结构适合复杂指令,但难以应对 AI 计算的简单指令下并行算力的要求。CPU通常包括控制器(Control),存储器(Cache、DRAM)和运算器(ALU),因为CPU内部大部分的晶体管用来构建存储器和控制器,其计算能力其实受到了很大制约。另外,无论是PC领域使用的X86架构还是在移动端覆盖率最大的ARM 架构,均是通过串行的方式执行指令,一般过程为从存储器中提取指令,进行解码,并利用运算器执行指令,逻辑遵从顺序结构,适应复杂逻辑。

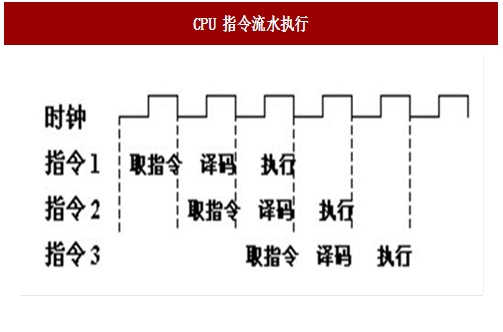
图:CPU 指令流水执行

图:CPU 结构
CPU 类似流水线,而 AI 技术更需要割麦机,前者适合复杂指令,后者适合大量数据并行处理。CPU处理数据的过程类似于工厂的流水线操作,流水线可以对单线程上每个产品做出不同处理,通用性强,适合处理复杂指令,擅长逻辑控制。但是前文提到的神经网络算法则是发出简单指令,而要求快速高效的并行计算能力,需要的数据处理过程更类似与割麦机收割麦子。我们可以想象如果使用流水线收割小麦并处理将会浪费多少的时间,因此使用CPU进行深度学习的效率比较低。此外,CPU主频速度受到功耗的影响提升空间有限,架构设计更新的周期也较长,无论从性能还是匹配度方面都不能满足AI计算的算力要求。在这种环境下,并行计算能力更强、适应于AI计算的AI芯片应运而生。
AI 芯片的业态简述和对比
用于 AI 计算的芯片按照是否为冯诺依曼架构以及是否为类脑芯片,可以分成多个类别。其中传统的CPU和GPU均属于冯诺依曼架构下的非类脑芯片,而ASIC、 FPGA和部分新一代GPU(如Nvidia的Tesla系列)则属于非冯架构下的非类脑芯片。类脑芯片与非类脑芯片的差异在于其不只是从功能上去模仿大脑而是从神经拟态架构层面去拟合大脑,如IBM的相变神经元架构就包括输入端、神经薄膜、信号发生器与输出端四个层面,与传统芯片设计理念差距较大。
图:AI 芯片的简单分类
GPU 因良好的矩阵计算能力和并行计算优势最早被用于 AI 计算,在数据中心中获得大量应用。GPU最早作为深度学习算法的芯片被引入人工智能领域,因其良好的浮点计算能力适用于矩阵计算,且相比CPU具有明显的数据吞吐量和并行计算优势。2011年谷歌大脑率先应用GPU芯片,当时12颗英伟达的GPU可以提供约等于2000颗CPU的深度学习性能,展示了其惊人的运算能力。目前GPU已经成为人工智能领域最普遍最成熟的智能芯片,应用于数据中心加速和部分智能终端领域,在深度学习的训练阶段其性能更是无所匹敌。
参考中国报告网发布《2018-2023年中国人工智能芯片市场发展现状与发展机遇分析报告》
FPGA 因其在灵活性和效率上的优势,适用于虚拟化云平台和预测阶段,在 2015 年后异军突起。2015年Intel收购FPGA市场第二大企业Altera,开始了FPGA在人工智能领域的应用热潮。因为FPGA灵活性较好、处理简单指令重复计算比较强,用在云计算架构形成CPU+FPGA的混合异构中相比GPU更加的低功效和高性能,适用于高密度计算,在深度学习的预测阶段有着更高的效率和更低的成本,使得全球科技巨头纷纷布局云端FPGA生态。国外包括亚马逊、微软都推出了基于FPGA的云计算服务,而国内包括腾讯云、阿里云均在2017年推出了基于FPGA 的服务,百度大脑也使用了FPGA芯片。

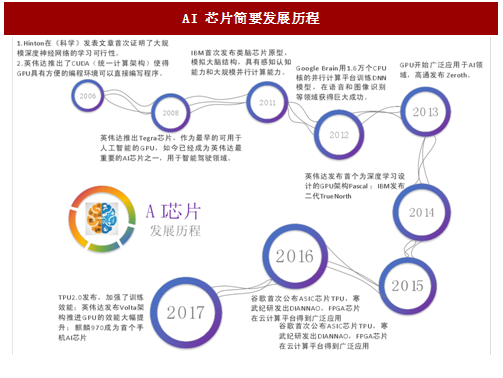
图:AI 芯片简要发展历程
ASIC 芯片因其比 FPGA 芯片具备更低的能耗与更高的计算效率,适用于人工智能平台和智能终端领域的特性,一直是 AI 芯片研发领域的焦点。但是ASIC研发周期较长、商业应用风险较大等不足也使得只有大企业或背靠大企业的团队愿意投入到它的完整开发中。其中最为出名的是Google在2016年开发的张量处理单元,即TPU芯片。在2017年最新版的AlphaGo物理处理器中就有4个TPU,同时TPU也支持着Google的Cloud TPU平台和基于此的机器学习超级计算机。此外,近期由国内企业寒武纪开发的 “DIANNAO”系列芯片受到广泛关注。华为新发的麒麟 970 处理器所搭载的 NPU 就是 2016 年寒武纪发布的 1A 处理器(Cambricon-1A Processor)。
类大脑芯片则在架构上直接通过模仿大脑结构进行神经拟态计算,完全开辟了另一条实现人工智能的道路,而不是作为人工神经网络或深度学习的加速器存在。类脑芯片可以将内存、CPU和通信部件完全集成在一起,实现极高的通信效率和极低的能耗。目前该类芯片还只是小规模研究与应用,低能耗的优势也带来预测精度不高等问题,没有高效的学习算法支持使得类脑芯片的进化较慢,还不能真正实现商用。目前这方面的代表是IBM的“True North”芯片。
总结来说,基于深度学习的应用过程,AI芯片可以分为适合训练使用(GPU)和适合预测使用(FPGA,ASIC);基于最终应用场景,则可以分为数据中心应用和广义终端应用。目前有的大部分现芯片都用于了深度学习的训练阶段,而随着终端的普及以及模型训练的不断完善,预测部分的计算占比将大幅提升。

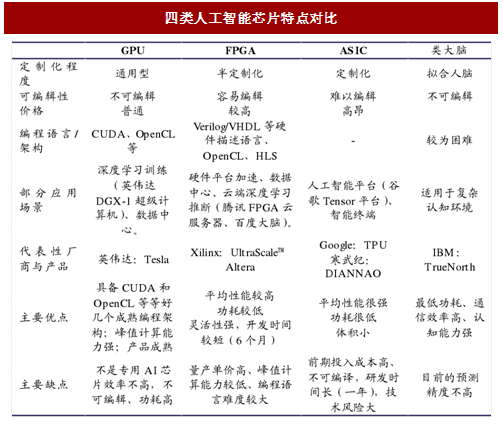
图:四类人工智能芯片特点对比

图:现有用于 AI 计算的部分芯片对比
资料来源:中国报告网整理,转载请注明出处(ZQ)
更多好文每日分享,欢迎关注公众号

【版权提示】观研报告网倡导尊重与保护知识产权。未经许可,任何人不得复制、转载、或以其他方式使用本网站的内容。如发现本站文章存在版权问题,烦请提供版权疑问、身份证明、版权证明、联系方式等发邮件至kf@chinabaogao.com,我们将及时沟通与处理。








