GPU(graphics processing unit,图形处理器)又被称为显示芯片,多用于个人电脑、工作站、游戏主机以及移动设备(智能手机、平板电脑、VR设备)上专门运行绘图运算的微处理器。
结构决定 GPU 更适合并行计算,GPU 与 CPU 主要区别在于片内的缓存体系和数字逻辑运算单元的结构差异:GPU核(尤其ALU运算单元)的数量远超CPU但是结构较CPU简单,因此被称为众核结构。众核结构非常适合把同样的指令流并行发送到众核上,采用不同的输入数据执行,从而完成图形处理中的海量简单操作,如对每一个顶点进行同样的坐标变换,对每一个顶点按照同样的光照模型计算颜色值。GPU 利用自身处理海量数据的优势,通过提高总的数据吞吐量(Throughput)来弥补执行时间(Latency)长的缺点。

参考观研天下发布《2018-2024年中国图形处理器(GPU) 行业市场发展现状调查及未来前景趋势研究报告》
矢量化编程与强大并行计算能力相契合,GPU 成为深度学习模型训练首选方案。矢量化((如矩阵相乘、矩阵相加、矩阵-向量乘法等)编程是提高算法速度的一种有效方法,深度学习中反向传播算法、 Auto-Encoder、卷积神经网络等都可以写成矢量的形式。CPU处理矢量运算方式为展开循环的串行执行,而 GPU 的众核体系结构包含几千个流处理器,可将矢量运算并行执行,大幅缩短计算时间。利用 GPU 对海量数据进行训练,所耗费的时间大幅缩短,占用的服务器也更少。


GPU 行业格局:由于AMD在通用计算及生态圈构建的长期缺位,深度学习 GPU 加速市场目前呈现 NVIDIA 一家独大的局面。根据 Mercury Research的统计,目前在“PC+工作器+服务器”独立GPU领域NVIDIA市占率接近70%。直到17年AMD才正式推出Radeon Instinct系列产品,主要面向深度学习和 HPC 数据中心应用。
结构决定 GPU 更适合并行计算,GPU 与 CPU 主要区别在于片内的缓存体系和数字逻辑运算单元的结构差异:GPU核(尤其ALU运算单元)的数量远超CPU但是结构较CPU简单,因此被称为众核结构。众核结构非常适合把同样的指令流并行发送到众核上,采用不同的输入数据执行,从而完成图形处理中的海量简单操作,如对每一个顶点进行同样的坐标变换,对每一个顶点按照同样的光照模型计算颜色值。GPU 利用自身处理海量数据的优势,通过提高总的数据吞吐量(Throughput)来弥补执行时间(Latency)长的缺点。

图表:CPU、GPU 结构差异导致应用不同

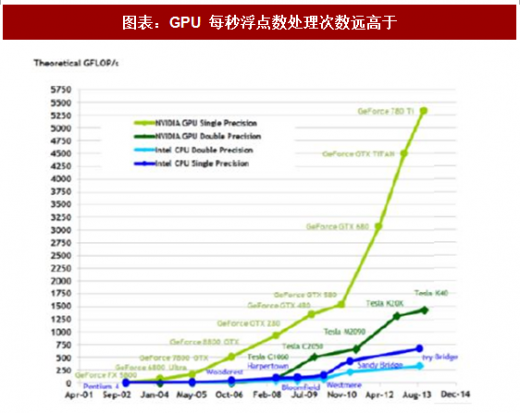
图表:GPU 每秒浮点数处理次数远高于
参考观研天下发布《2018-2024年中国图形处理器(GPU) 行业市场发展现状调查及未来前景趋势研究报告》
矢量化编程与强大并行计算能力相契合,GPU 成为深度学习模型训练首选方案。矢量化((如矩阵相乘、矩阵相加、矩阵-向量乘法等)编程是提高算法速度的一种有效方法,深度学习中反向传播算法、 Auto-Encoder、卷积神经网络等都可以写成矢量的形式。CPU处理矢量运算方式为展开循环的串行执行,而 GPU 的众核体系结构包含几千个流处理器,可将矢量运算并行执行,大幅缩短计算时间。利用 GPU 对海量数据进行训练,所耗费的时间大幅缩短,占用的服务器也更少。

图表:模型并行的基本架构

图表:GPU 在深度学习训练中表现出众
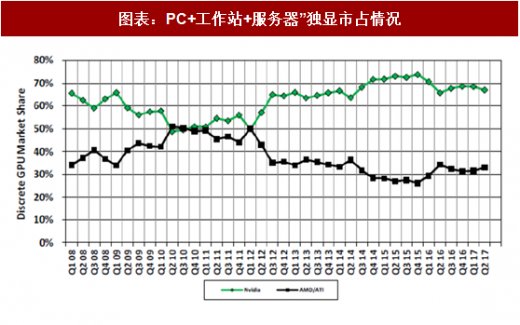
GPU 行业格局:由于AMD在通用计算及生态圈构建的长期缺位,深度学习 GPU 加速市场目前呈现 NVIDIA 一家独大的局面。根据 Mercury Research的统计,目前在“PC+工作器+服务器”独立GPU领域NVIDIA市占率接近70%。直到17年AMD才正式推出Radeon Instinct系列产品,主要面向深度学习和 HPC 数据中心应用。

图表:PC+工作站+服务器”独显市占情况

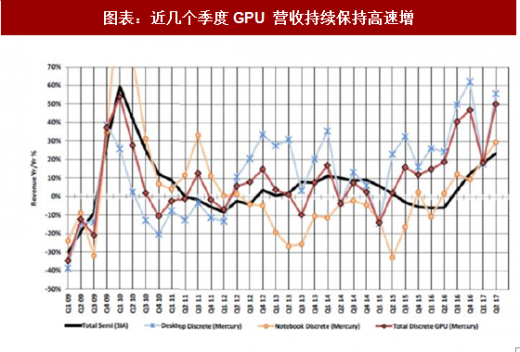
图表:近几个季度GPU 营收持续保持高速增

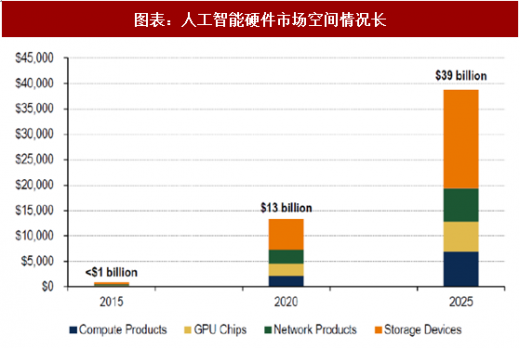
图表:人工智能硬件市场空间情况长
资料来源:观研天下整理,转载请注明出处(ZQ)
更多好文每日分享,欢迎关注公众号

【版权提示】观研报告网倡导尊重与保护知识产权。未经许可,任何人不得复制、转载、或以其他方式使用本网站的内容。如发现本站文章存在版权问题,烦请提供版权疑问、身份证明、版权证明、联系方式等发邮件至kf@chinabaogao.com,我们将及时沟通与处理。